Блог им. Anganar → Архитектура корпоративной ИС на базе открытого ПО
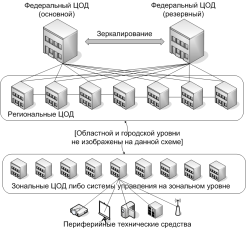 По опыту на сегодняшний день большинство организаций уже отлично понимают, что открытое ПО дает много новых возможностей. Но при этом «как его готовить» разобрались далеко не все. Одна из причин этого — огромное разнообразие продуктов и решений с открытым кодом. Для разработчиков, администраторов и прочих ИТ-профессионалов это плюс — всегда можно найти что-то новое, интересное и полезное. Но когда речь заходит о серьезных внедрениях в корпоративном секторе, разнообразие тут же превращается в минус — неясно что выбирать, чему верить, к кому обращаться, какие решения гарантированно работают и качественно поддерживаются.
По опыту на сегодняшний день большинство организаций уже отлично понимают, что открытое ПО дает много новых возможностей. Но при этом «как его готовить» разобрались далеко не все. Одна из причин этого — огромное разнообразие продуктов и решений с открытым кодом. Для разработчиков, администраторов и прочих ИТ-профессионалов это плюс — всегда можно найти что-то новое, интересное и полезное. Но когда речь заходит о серьезных внедрениях в корпоративном секторе, разнообразие тут же превращается в минус — неясно что выбирать, чему верить, к кому обращаться, какие решения гарантированно работают и качественно поддерживаются.Одним из приоритетов группы компаний VDEL, в которой я работаю, является формирование полного стека открытого ПО, который бы закрывал все типовые ИТ-потребности организации и соответствовал требованиям корпоративных заказчиков (гарантированная официальная техническая поддержка, сертификации, стабильность развития и т.д.).
В результате работы в этом направлении возник обзорный архитектурный документ, описывающий построение на основе открытого ПО ИТ-инфраструктуры большой распределенной организации. Текущая рабочая версия документа является публичной, так что я могу ее выложить.
Документ выложен здесь — .
Комментарии и конструктивная критика приветствуются.
P.S. Кросс-пост из личного блога
- +6
- Anganar
- 13 января 2010, 14:06
Только хотелось бы иметь возможность как-то этот документ поиметь в более удобном для работы формате.
выложте куда-нибудь файлик, чтоб без рега скачать
Смотрел невнимально, но вроде предполагается независимость от используемой БД. Имеется в виду, что в конечном проекте можно использовать любую или что БД можно заменить не меняя ничего в остальной системе (кроме настроек)?
В роли СУБД здесь — EDB/Postgres. Горизонтальное масштабирование — средствами GridSQL ().
Насчет заменяемости компонент (СОА, интероперабельность и все подобные правильные слова) — мысли поработать в эту сторону есть, но сил пока не хватает.
P.S. Боюсь, что у меня слишком специфические задачи для GridSQL, но попробовать стоит.
К данным архива как раз можно применить горизонтальную кластеризацию, но даст ли это какое-то преимущество? Т.к. моя проблема не в тяжести запросов, а в их количестве и взаимосвязанности, ну и само собой архивная БД имеет огромные объемы + нагрузка от пользователей, которые как раз делают тяжелые запросы в архив.